当我们享受着jdk带来的便利时同样承受它带来的不幸恶果。通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,安全的背后是巨大的浪费,而现在的解决方案----ConcurrentHashMap。
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁。如图
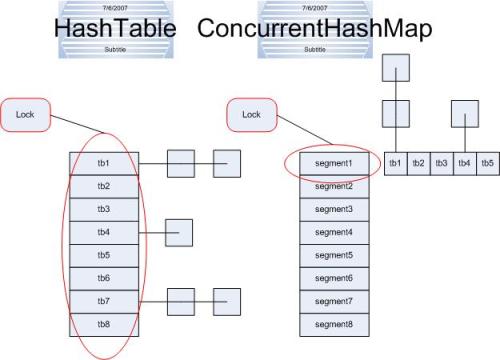
左边便是Hashtable的实现方式---锁整个hash表;而右边则是ConcurrentHashMap的实现方式---锁桶(或段)。ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
接下来,让我们看看ConcurrentHashMap中的几个重要方法,心里知道了实现机制后,使用起来就更加有底气。
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应上面的图可以看出之间的关系。
get方法(请注意,这里分析的方法都是针对桶的,因为ConcurrentHashMap的最大改进就是将粒度细化到了桶上),首先判断了当前桶的数据个数是否为0,为0自然不可能get到什么,只有返回null,这样做避免了不必要的搜索,也用最小的代价避免出错。然后得到头节点(方法将在下面涉及)之后就是根据hash和key逐个判断是否是指定的值,如果是并且值非空就说明找到了,直接返回;程序非常简单;相对于之前的Hashtable,并发是不可避免的啊!
public V get(Object key) { Node [] tab; Node e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; } put操作一上来就锁定了整个segment,这当然是为了并发的安全,修改数据是不能并发进行的,必须得有个判断是否超限的语句以确保容量不足时能够rehash,,原来segment里面才是真正的hashtable,即每个segment是一个传统意义上的hashtable,如上图,从两者的结构就可以看出区别,这里就是找出需要的entry在table的哪一个位置,之后得到的entry就是这个链的第一个节点,如果e!=null,说明找到了,这是就要替换节点的值if(!onlyIfAbsent),否则,我们需要new一个entry,它的后继是first,而让tab[index]指向它,什么意思呢?实际上就是将这个新entry插入到链头,剩下的就非常容易理解了。
public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node [] tab = table;;) { Node f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node (hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node pred = e; if ((e = e.next) == null) { pred.next = new Node (hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node p; binCount = 2; if ((p = ((TreeBin )f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; } remove操作非常类似put,但要注意一点区别,中间那个for循环是做什么用的呢?从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。
public V remove(Object key) { return replaceNode(key, null, null); } /** * Implementation for the four public remove/replace methods: * Replaces node value with v, conditional upon match of cv if * non-null. If resulting value is null, delete. */ final V replaceNode(Object key, V value, Object cv) { int hash = spread(key.hashCode()); for (Node [] tab = table;;) { Node f; int n, i, fh; if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null) break; else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; boolean validated = false; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { validated = true; for (Node e = f, pred = null;;) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { V ev = e.val; if (cv == null || cv == ev || (ev != null && cv.equals(ev))) { oldVal = ev; if (value != null) e.val = value; else if (pred != null) pred.next = e.next; else setTabAt(tab, i, e.next); } break; } pred = e; if ((e = e.next) == null) break; } } else if (f instanceof TreeBin) { validated = true; TreeBin t = (TreeBin )f; TreeNode r, p; if ((r = t.root) != null && (p = r.findTreeNode(hash, key, null)) != null) { V pv = p.val; if (cv == null || cv == pv || (pv != null && cv.equals(pv))) { oldVal = pv; if (value != null) p.val = value; else if (t.removeTreeNode(p)) setTabAt(tab, i, untreeify(t.first)); } } } } } if (validated) { if (oldVal != null) { if (value == null) addCount(-1L, -1); return oldVal; } break; } } } return null; }